The Palmer Penguins Dataset
A brief blog about my new favourite toy dataset
Meeting The Iris Dataset
I started my Python journey in 2017, using Jupyter to learn the usual scientific computing suspects like matplotlib, pandas, scipy and numpy. I remember the day I found Seaborn - I was thrilled by the array of colourmaps and the easy-to-make-pretty graphs. I quickly made coloured copies of a Spiderman image.
In 2018 as I veered into machine learning territory, I got myself a CSV copy of the Iris Dataset. If you haven’t met it before, it is ubiquitous in ML - it’s a nice clean dataset with:
- 150 photos of Iris flowers,
- 4 captured variables (petal lengths etc.)
- 3 species of Iris flowers.
.jpg)
The goal is to build a model to classify images by species. The dataset’s popularity is largely driven by its small size, easy access and data-cleanliness.
More importantly for this post, with a few simple plots you can start to see which variables might indicate a difference in species and see some tidy clustering. Before you know it, you’re learning about data visualisation and multivariable classification methods and annoying your friends with your newfound knowledge. Welcome to ML.
Fash-on
Before long I was exposed to all the standard datsets - CIFAR-10, the Boston Housing Dataset, the Stanford Natural Language Inference Corpus… and MNIST, a datset consisting of handwritten numbers from 0-9.

Your task? Train an algorithm to recognise the numbers correctly. This one is fun because while only a botanist might see the value of flower classification, non-scientists can see the intrigue in being able to read handwriting with computers.
One day while reading a paper, I found something called Fashion-MNIST - instead of handwritten digits, we had a dataset with photos of different categories of clothes - jackets, boots, skirts, etc. It was touted as the new MNIST - slightly larger and slightly more difficult, to match the rapidly advancing capabilities of ML.
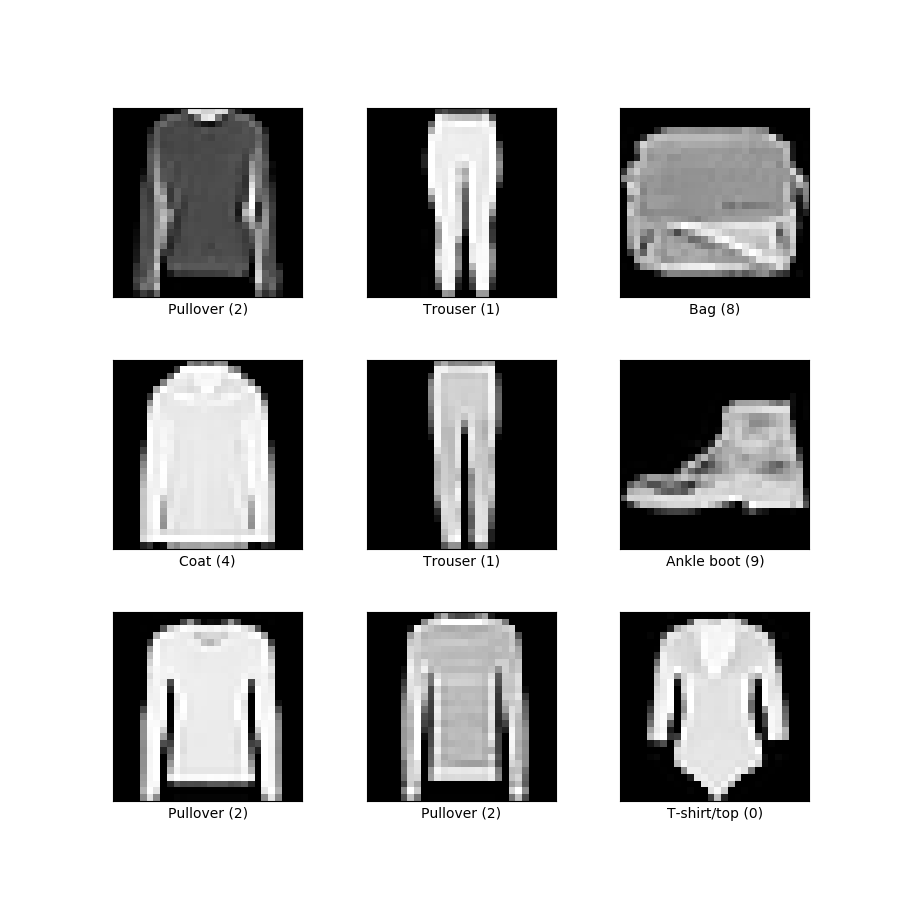
I was thrilled by the idea of an “upgraded” datset consisting entirely of something as random as clothing. I felt like a real academic, discovering new data in papers. I was so fond of this cool new dataset that I used it to implemenmt encrypted logistic regression in C++. I delighted in introducing the dataset in the paper I worked on.
Into the woods
Since then, I’ve met a lot of interesting (mostly image) datasets - everything from chest x-rays and skin lesions, to mammoths like Imagenet and COCO, and even some real world reference data.
Despite this exposure, I’ve always gone back to Iris when I’m working with something new. Testing new hardware? Building a new Python environment? Just want to make some pretty graphs? Well, Iris is built into a bunch of Python libraries, it’s fast to load, and it feels like a book I’ve read 100 times, meaning I can focus on whatever problem I’m solving instead of on the peculiarities of the data.
And so last week when I was asked to mock up some pretty plots, I figured I’d use ye-olde-iris to get the job done. I searched for something like “iris pairplot seaborn” to jog my memory. Within the search results was a link titled IRIS ALTERNATIVE - PALMER PENGUINS.
Introducing the Palmer Penguins.
All the excitement I felt upon finding the Fashion-MNIST was reborn in that moment. An alternative to Iris? WITH PENGUINS? I was sold.
The Palmer Penguins dataset has 300+ penguin samples captured from the Palmer Archipelago. It’s almost a one-for-one stand in for Iris, coming with some extra categorical data (species, island, and sex.). This meant I was in very familiar territory, with some added intrigue.
I immediately set about to producing my charts with this shiny new data. I quickly learned that heavier penguins had longer flippers. Of course, being very far removed from penguin research, I hypothesised that maybe bigger flippers = faster swimming = more fish, or maybe bigger penguins are just bigger all over, or maybe fatter penguins have the resources needed to grow longer flippers, or…
Brilliant. I was thinking about chunky penguins instead of flower petals - what’s not to love?
And so this blog post is a short callout to the Palmer Penguin dataset and the joy it brought me. I can only wish for fashion-penguins on the horizon…

ABOUT Tea, Tech and Trials
A place to blog the things I'm working on - from tech to infinity and beyond.
Kiowa Scott-Hurley